
Podcast: Reproducir en una nueva ventana | Descargar
Bienvenidos al trigésimo-segundo capítulo del podcast de seguridad informática «Securizando.com»
Soy Andreu Adrover y hoy es viernes 19 de enero de 2018.

Aunque la idea inicial de este capítulo era ser la continuación del podcast 31 y hablar sobre las defensas específicas para los ataques DDoS vía el protocolo HTTP, creo que lo preferible será hacer un capítulo explicando las defensas generales que podemos activar ante ataques DDoS para posteriormente ya centrarme, en otro capítulo, en las técnicas de defensa específicas de HTTP, DNS y demás protocolos. Así pues hoy hablaremos de técnicas genéricas de defensa frente ataques de denegación de servicio. Hay que tener en cuenta que todas estas técnicas (y cualquier en la seguridad informática en general) requieren de una preparación previa: improvisar durante un incidente (un ataque de denegación en este caso) suele ser la receta perfecta para liar más la situación.
Capacidad de crecimiento
Con el desarrollo de los entornos virtuales las posibilidades de adaptación de los sistemas a los requerimientos de los usuarios se ha visto potenciada. Ahora es normal que las aplicaciones modifiquen sus capacidades en función de la necesidad y del coste asociado: ya no es extraño que durante las horas valle de uso se reduzca el número de servidores mientras que en las horas punta la capacidad del sistema aumente. El hecho de que los entornos virtuales en la nube tenga un coste por uso, ha fomentando en gran medida esta variabilidad del entorno.
Número servidores (crecimiento horizontal)
Actualmente, la primera opción que nos suele venir a la cabeza en caso de necesitar tratar más conexiones de las habituales es ampliar el número de servidores. Los sistemas virtuales permiten añadir nuevos servidores a la granja de forma rápida y relativamente sencilla. Aumentando el número de servidores se consigue dar servicio a más conexiones, aunque como todo en la vida, siempre hay un límite que no podremos superar (capacidad de transacciones de la base de datos, capacidad de escritora en discos, capacidad de ancho de banda, etc…). Esta crecimiento se denomina horizontal ya que lo que se hace ganar capacidades añadiendo nuevos servidores a la granja y es ampliamente utilizada en las aplicaciones web o distribuidas.
Capacidad sistema (crecimiento vertical)
En contraposición al sistema anterior, el crecimiento vertical consiste en aumentar la capacidad de los propios nodos del sistema: aumentar la memoria o velocidad de CPU, aumentar la capacidad de disco (ya sea ampliando los filesystems o creando nuevos). Esta estrategia suele tener un mayor coste de aplicación (muchas veces implica reiniciar el servidor para que el sistema operativo tome en cuenta las nuevas capacidades). Así pues se trata de una estrategia más pesada, pero que sería necesaria cuando el cuello de botella se encuentra en sistemas únicos (bases de datos, aplicaciones mainframe, etc.).
Capacidad línea comunicaciones
Otro punto donde un ataque de denegación de servicio suele ser las propias líneas de comunicaciones. Así aunque el servicio esté operativo si los clientes no pueden llegar a él ya se ha conseguido la denegación de servicio. En los grandes servicios en la nube (AKAMAI, Amazon, Azure, etc.) es un punto que ya está resuelto en su infraestructura propia, pero para aquellos servicios de hosting más pequeños es algo a tener en cuenta. Para aquellas empresas que tienen sus servicios alojados en su propio centro, las operadoras ofrecen líneas de comunicaciones con diferentes capacidades de crecimiento que hay que evaluar: no es extraño contratar una línea de fibra óptica con capacidad de de 1Gbps pero de los que se usan (y pagan) 400Mbps. Así en caso de problemas, simplemente se amplía la capacidad de la línea. Obviamente esta ampliación rápida debe estar acordada previamente con la operadora (cómo se solicita la ampliación, quién está autorizado a solicitarla, y cómo se pagará después ;))
Sistemas IPS – WAF
Como ya vimos en los capítulos 4 y 29 los sistemas IPS y WAF permiten detectar y bloquear tráfico anómalo mediante el análisis del tráfico que pasa por sus interfaces. Las firmas de detección pueden ser múltiples y dependerán del protocolo utilizado para el ataque: por ejemplo si suponemos un ataque web donde se envía a través de formulario un archivo adjunto grande para saturar las capacidades del sistema, un WAF podría detectar que los usuarios no han seguido el camino normal (acceso a portada, clic en opción de envío, etc.) y que sólo envían directamente el formulario. En este caso el sistema podría descartar el tráfico que no haya seguido el cauce habitual con lo que se descartarían los ataques con mínima afectación a los usuarios habituales.
Listas negras (Direcciones IP de botnet, nodos Tor…)

Fuente imagen: Fakrul Alam en SlideShare.net
Actualmente muchos proveedores de sistemas de seguridad mantienen una serie de listas con direcciones IP de baja o mala reputación que pueden utilizarse para descartar tráfico proveniente de ellas. Estas listas de direcciones IP incluyen equipos que se ha descubierto que pertenece a una botnet (y por ello es probable que en caso de ataque de denegación de servicio sean una de las causantes), que han sido utilizadas en ataques previos o, por ejemplo que son nodos de salida de la red Tor. La red Tor no es intrísicamente maliciosa, pero hay que entender que utilizar este servicio de anonimato para acceder a una aplicación web que debe autenticarse (pago con tarjeta, acceso mediante usuario/contraseña…) no parece una opción muy lógica. Así pues si estamos ante un ataque de denegación de servicio una opción rápida es bloquear el tráfico proveniente de estas direcciones IP de dudosa reputación. Es posible que perdamos algún cliente (porque desconoce que sus equipos formen parte de una botnet), así que no siempre es aconsejable tener estos filtros activados siempre.
Bloqueo por ubicación geográfica
Los rangos de direcciones IP son asignados por la IANA (Internet Assigned Numbers Authority), en base a unos cálculos de necesidades previstas, de forma distribuida por países. Así pues es posible conocer el supuesto país de origen de una conexión por Internet por esta asociación. Si bien hay un cierto mercadeo de direcciones donde una empresa multinacional compra direcciones de un país donde tengan libres (actualmente principalmente de países africanos) para luego utilizarlas en otras ubicaciones, esta ubicación geográfica es aún bastante correcta.
Por ello una posible estrategia en caso de sufrir un ataque de denegación de servicio sería bloquear el tráfico proveniente de países donde nuestra empresa no tenga mercado. Por ejemplo si nuestra empresa alquila coches en España es poco probable que nuestro servicio reciba demasiadas peticiones legítimas desde Laos o Tanzania, mientras que sí es muy probable que reciba peticiones desde los principales clientes turísticos (Alemania, Reino Unido…). En cambio si nuestra empresa se dedica al transporte internacional por carretera no será extraño recibir peticiones desde Polonia o Ucrania. En caso de ataque el hecho de descartar todo el tráfico salvo el que provenga de los principales mercados de nuestra empresa mitigará en gran medida el ataque con una afectación mínima a nuestros principales clientes.
Modificación parámetros de protocolos
Casi los primeros ataques de denegación de servicio que aparecieron tratan de aprovechar los tiempos de espera entre transacciones definidos en los distintos protocolos. Así cuando, por ejemplo, establecemos una conexión TCP (que son necesarias para la mayoría de protocolos usados para navegar, enviar correos electrónicos, etc.), los estándares indican un tiempo máximo en la negociación de dicha conexión. Un usuario malicioso pueden intentar alargar al máximo el tiempo de envío entre paquetes para asegurar así que el receptor reserva durante el máximo tiempo posible sus capacidades (espacio de memoria, tiempo procesador…). Igualmente puede iniciar una conexión pero sin finalizar el proceso de establecimiento por lo que nuestro servidor se quedaría a la escucha (usando recursos) para, pasado el tiempo, descartar ese paquete inicial. Una estrategia para liberar recursos rápidamente es acortar estos tiempos de espera y descartar tráfico posiblemente malicioso antes, de tal forma que se pueda seguir recibiendo nuevas peticiones. Igualmente el sistema podría simplemente descartar paquetes malformados, con errores de transmisión, con un excesivo desorden, etc. en vez de solicitar retransmisiones, evitando así tener que realizar reservas de recursos.
Actualmente estos ataques no suelen verse de forma independiente sino que suelen acompañar a otros ataques usando protocolos de mayor nivel, pero aún así el hecho de mitigarlos permite a la infraestructura liberar recursos más rápidamente.
Aunque como teleco ‘me duela’ romper los estándares, hay que tener en cuenta que se trataría de una medida de mitigación de un ataque. El hecho de reducir estos tiempo podría influir negativamente a nuestros clientes con menores capacidades (ancho de banda más limitado, etc.) pero claro, ante un ataque de denegación de servicio hay que elegir el mal menor.
Servicios anti DDoS:
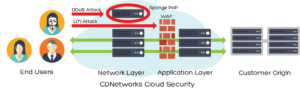
Actualmente se pueden contratar servicios “en la nube” que mitiguen estos ataques de denegación de servicio gracias a sus mayores capacidades. En este punto existen dos enfoques principales: tener el servicio activo siempre de forma que todo el tráfico pasa por los sistemas del proveedor o bien activarlo únicamente en caso de necesidad. Por obvios motivos esta activación según necesidad requiere de una planificación y acuerdo previo, ya que no se puede improvisar sobre la marcha durante un ataque (aunque los comerciales de estas empresas estarán encantados de decirte que sí que es posible).
Aunque más adelante le dedicaremos un capítulo a qué ofrecen estos servicios, cómo funcionan, cómo puede realizarse la derivación del tráfico, etc. podemos resumir su función como una de estas dos opciones:
Filtrado de paquetes (firewall): permiten que sólo el tráfico del protocolo elegido llegue a nuestros servidores. Así nuestra infraestructura no recibe los ataques siplementarios (tráfico UDP, inundaciones SYN, malformación de paquetes, etc.).
Actúan como proxy: Los clientes se conectan a su infraestructura y es ésta la que se conecta a nuestros servidores. Así todas aquellas conexiones fraudulentas son descartadas por el proveedor y no llegan a nuestros servidores (evitando la denegación de servicio).


Fuente imagen: PerfectYourPodcast
Como podéis observar muchas de estas protecciones (tener capacidades de crecimiento no usadas, contratar los servicios de anti-DDoS, mantenimiento de sistemas IPS o WAF,…) implican un coste económico, por lo que una empresa debe evaluar hasta que punto quiere llevar la protección de sus sistemas. Teniendo en cuenta que por temas legales hay una serie de sistemas defensivos que deben estar activos, desde el punto de vista económico hay que evaluar los riesgos y actuar en consecuencia: no sería lógico gastarse miles de euros al mes en un sistema para defender una pequeña tienda de camisetas online cuya caída durante un día completo implique unas pérdidas menores al coste del sistema de defensa. Las grandes empresas deben tener en cuenta los costes intangibles (daño a la imagen de marca, cumplimiento de SLA con proveedores, etc.).





{kind=link}
{kind=link}